Datenextraktion ist der Prozess, Informationen aus physischen Dokumenten, PDFs, Kundenprofilen und anderen Quellen zu gewinnen und diese für Wettbewerbsanalysen zu nutzen. Auch heute noch verarbeiten viele Unternehmen Daten manuell – ein zeitaufwendiger und fehleranfälliger Prozess.
Mit automatisierter Datenextraktionssoftware kann diese Verarbeitungszeit jedoch erheblich reduziert und die Genauigkeit verbessert werden, was die Organisation der Daten erheblich erleichtert. Aus Dokumenten extrahierte Texte können elektronisch gespeichert, online geteilt oder in verschiedenen Dateiformaten für künftige Analysen gesichert werden.
Was ist Datenextraktion?
Datenextraktion bezieht sich auf den Prozess der Informationsgewinnung aus einer Vielzahl von Dokumenten.
Unternehmen extrahieren Daten, um sie zu verarbeiten, zu analysieren und für weitere Zwecke zu nutzen.
Viele Führungskräfte verbringen über 25 % ihrer Zeit damit, manuell Daten in Systeme einzugeben und operative Informationen zu überprüfen – Prozesse, die vollständig automatisiert werden könnten.

Datenextraktion bedeutet, wichtige Informationen aus Dokumenten zu entnehmen und für geschäftliche, persönliche, finanzielle oder rechtliche Zwecke zu nutzen.
Obwohl viele Programme zur Texterkennung verfügbar sind, zeichnet sich PaperOffice durch den Einsatz von KI und intelligenter OCR-Technologie aus, die eine automatische und präzise Texterkennung sowie -extraktion ermöglicht – ganz ohne Training, Einlernen oder Vorlagen.
Seit über 20 Jahren ist PaperOffice führend im Bereich des Dokumentenmanagements und bietet fortschrittliche Lösungen zur Automatisierung von Geschäftsprozessen.
Die kontinuierliche Entwicklung moderner Technologien zur Texterkennung und Datenextraktion ermöglicht es Unternehmen, Dokumente effizienter zu verarbeiten und zu organisieren.
Dank der KI-gestützten OCR-Technologie liefert PaperOffice zuverlässige und genaue Ergebnisse, die den Arbeitsalltag deutlich vereinfachen.
Warum sollte ein Unternehmen Daten extrahieren?
Datenextraktion ist für Unternehmen essenziell, um wertvolle Informationen aus verschiedenen Dokumenten zu gewinnen und effizient weiterzuverarbeiten.
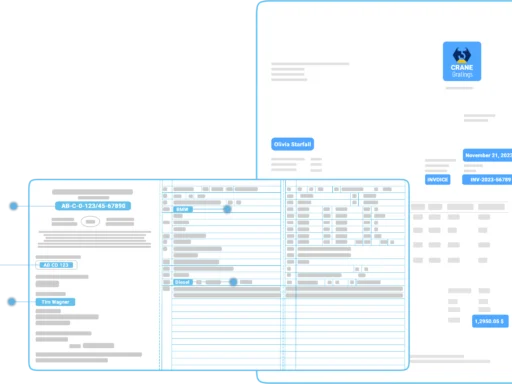
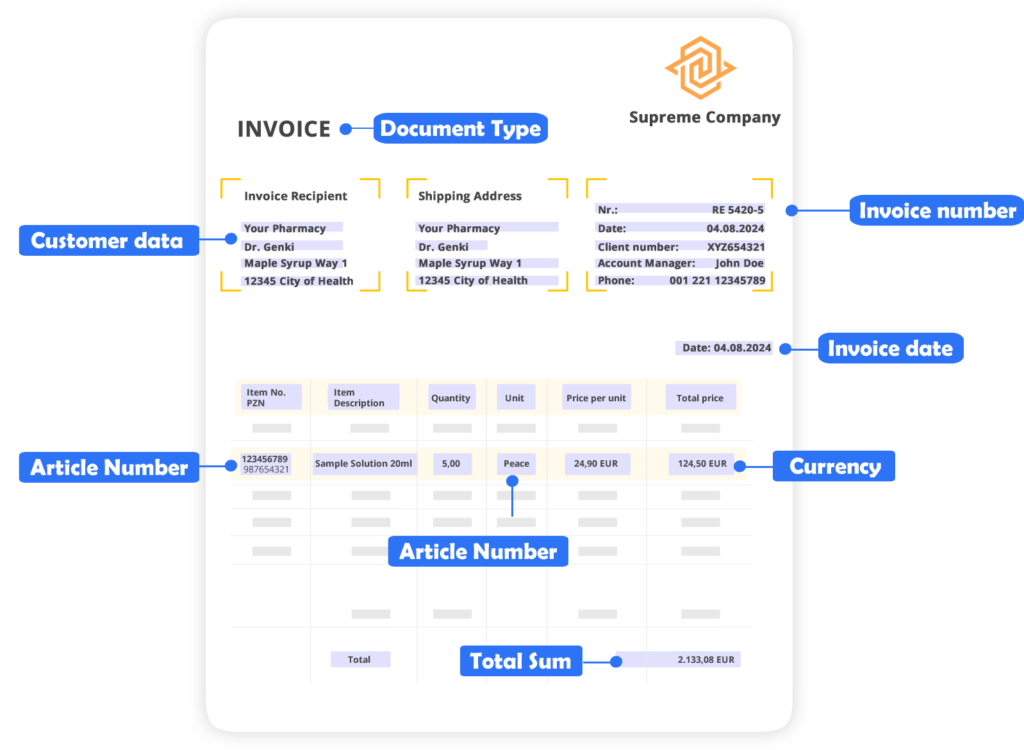
Zum Beispiel können Lieferscheine automatisch analysiert werden, um Artikelnummern, Mengen und Lieferdaten präzise zu erfassen.
Diese Daten werden direkt in interne Systeme übertragen, was eine schnellere Verarbeitung ermöglicht und Fehler bei der manuellen Eingabe vermeidet.

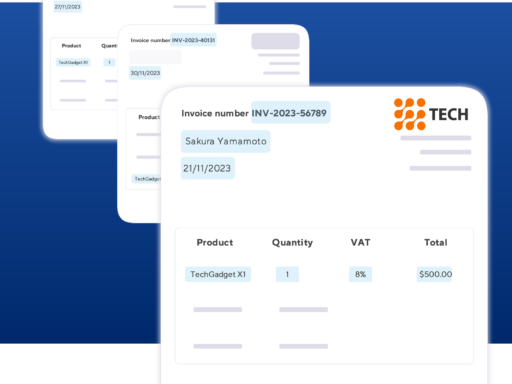
Ein weiteres Beispiel ist die Verarbeitung von Rechnungen. Hier können durch die automatisierte Datenextraktion Rechnungsbeträge, Zahlungsfristen und Kundendaten erfasst werden, ohne dass Vorlagen benötigt werden.
So wird der gesamte Rechnungsprozess beschleunigt und vollständig digitalisiert.
Auch im rechtlichen Bereich, wie etwa bei Verträgen, kann durch die automatisierte Extraktion von Vertragsklauseln oder wichtigen Fristen sichergestellt werden, dass keine kritischen Daten übersehen werden.
Dies hilft Unternehmen, Fristen einzuhalten und die Einhaltung rechtlicher Verpflichtungen zu gewährleisten.
Manuelle vs. automatisierte Datenextraktion – Ein Vergleich:
| Manuelle Dateneingabe | Automatisierte Dateneingabe | |
|---|---|---|
| Volumen | Kann große Datenmengen nicht in Sekunden verarbeiten und führt zu Engpässen bei der Kundenreaktionszeit. | Schnellere Kundenreaktionen durch die schnelle Verarbeitung großer Datenmengen. |
| Anfangskosten | Mitarbeiter stundenweise zu beschäftigen, kann anfangs günstiger sein, aber die langfristigen Kosten steigen erheblich. | Die Anfangsinvestition ist höher, aber die langfristige Rendite ist garantiert. |
| Verarbeitung | Daten müssen überprüft, validiert und auf Fehlerfreiheit geprüft werden. Fehler wie Duplikate oder falsche Extrakte erfordern eine erneute Bearbeitung. | Keine Nachbearbeitung erforderlich, da alle Daten automatisch durch das System verifiziert und validiert werden. |
| Menschlicher Eingriff | Dateneingabekräfte müssen die Struktur unterschiedlicher Dokumente erlernen und sich anpassen. Ihre Geschwindigkeit ist begrenzt. | KI und maschinelle Lernalgorithmen passen sich automatisch an Dokumentenstrukturen an, ohne menschliches Eingreifen. Die Verarbeitungszeit ist schnell. |
| Genauigkeit | Die Fehlerquote bei manueller Datenextraktion liegt zwischen 3 % und 30 %. | Automatisierte Datenextraktion erreicht durchgehend eine Genauigkeit von bis zu 99,9 %. |
Weitere Vorteile der automatisierten Datenextraktion für Unternehmen:
Mehr Kunden gewinnen:
Unternehmen, die Daten effizient extrahieren, organisieren und speichern, machen es einfacher, Kundenvertrauen zu gewinnen.
Durch das richtige Management von Kundendaten und deren sichere Verarbeitung können Unternehmen ihre Glaubwürdigkeit steigern.
Erfüllung rechtlicher Anforderungen:
Versicherungen, Investoren und Kunden verlangen oft eine rechtliche Konformität bei der Verarbeitung von Dokumenten.
Mit der digitalen Speicherung können Dokumente durchsucht, archiviert und sicher aufbewahrt werden.
Automatisierte Datenextraktion : ganz ohne Aufwand
Mit PaperOffice entfällt das stundenlange, aufwendige Einlernen von Dokumentenstrukturen, das oft mit hohen Kosten verbunden ist.
Unsere Lösung benötigt weder komplizierte Regex-Muster noch vordefinierte Vorlagen, um Daten zuverlässig zu extrahieren.
Die KI-Technologie erkennt automatisch relevante Informationen wie Namen, Beträge, Artikelnummern oder Daten, unabhängig von ihrer Anordnung im Dokument.
Dies spart nicht nur wertvolle Zeit und Ressourcen, sondern bietet auch maximale Flexibilität, da das System ohne manuelle Anpassungen problemlos mit verschiedenen Dokumententypen arbeitet.
Warum Sie automatisierte Datenextraktion in Betracht ziehen sollten
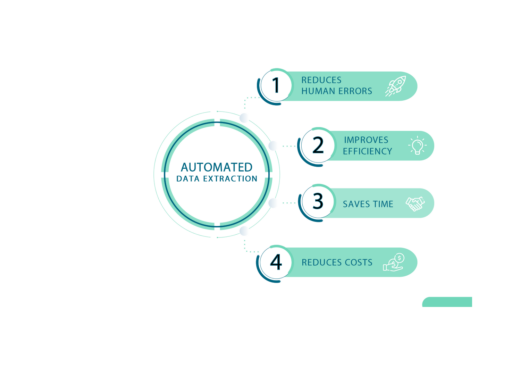
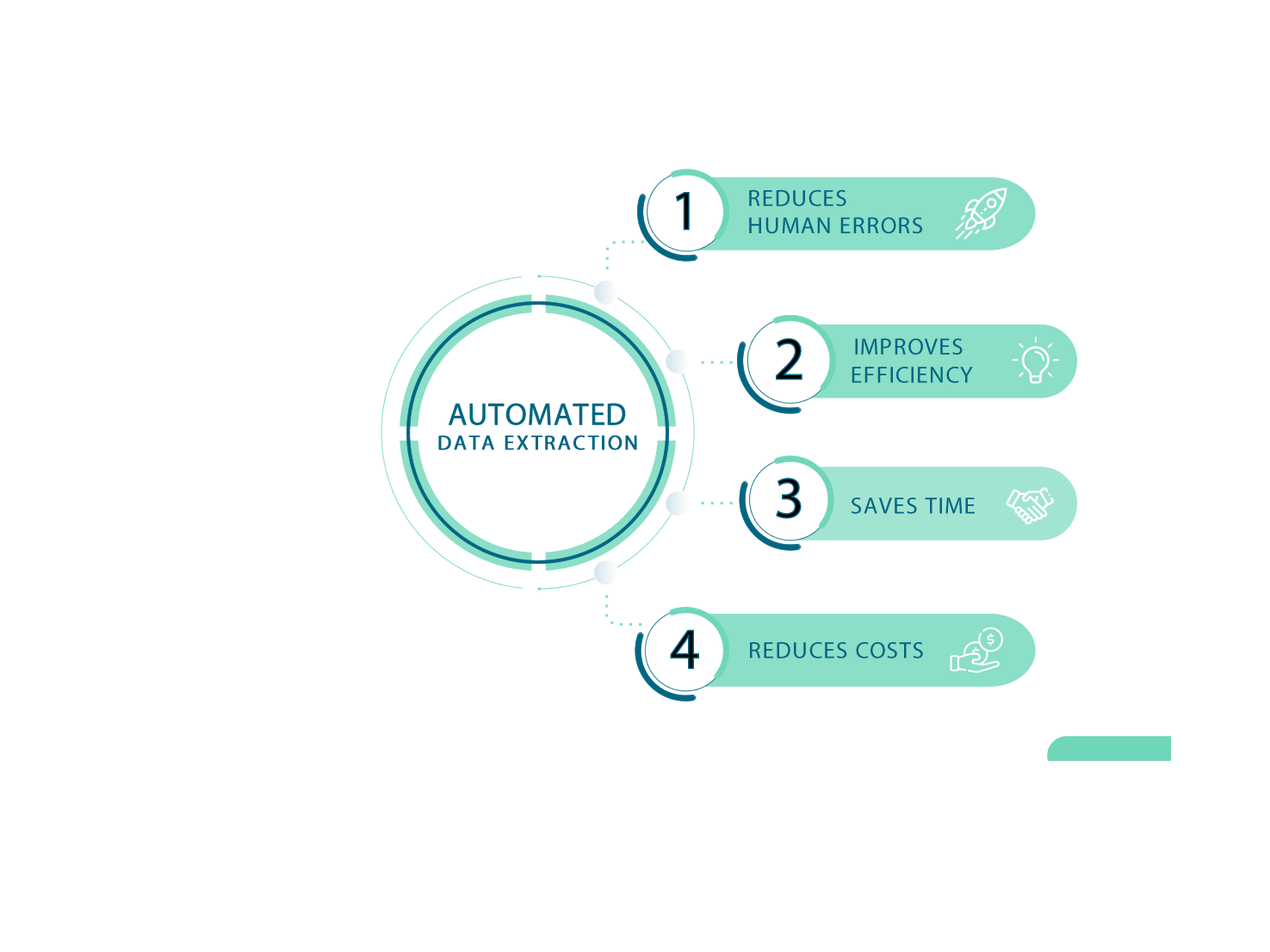
Eliminierung von menschlichen Fehlern:
Automatisierte Datenextraktionstechnologien helfen, menschliche Fehler bei der Dateneingabe zu vermeiden, was die Entscheidungsgenauigkeit und den langfristigen Erfolg verbessert.
Effizienzsteigerung:
Mit automatisierter Datenextraktion können Mitarbeiter von monotonen Aufgaben entlastet und für produktivere Tätigkeiten eingesetzt werden.
Dies steigert die Effizienz des Unternehmens insgesamt.
Zeitersparnis:
Die manuelle Bearbeitung tausender Dokumente ist zeitaufwendig. Mit automatisierter Datenextraktion kann diese Arbeit in Minuten erledigt werden, was Geschäftsprozesse beschleunigt.
Speicherung in verschiedenen Formaten:
Die extrahierten Daten können in verschiedenen Formaten wie EXCEL, JSON oder CSV gespeichert werden, was die spätere Analyse und Nutzung erleichtert.
Fazit
Datenextraktion ist der erste Schritt in vielen Datenverarbeitungsprozessen und ermöglicht es Unternehmen, Daten zentral zu speichern, zu konsolidieren und ihre Integrität sicherzustellen.
PaperOffice bietet eine zuverlässige und automatisierte Lösung zur Datenextraktion, die Unternehmen hilft, Prozesse zu optimieren und wertvolle Erkenntnisse zu gewinnen.

Amina is a self-taught Machine Learning expert with a strong focus on applying AI in industries such as logistics, eCommerce, health-tech, linguistics, and Document AI. Leveraging her skills in Machine Learning, Natural Language Processing, and MLOps, she helps PaperOffice create fully automated document processing solutions, improving workflows and driving efficiency.